
WHAT IS TEXT MINING?
Text mining (also referred to as Text Analytics)is an artificial intelligence (AI) tool that converts unstructured text into a structured format using natural language processing in order to find significant patterns and fresh perspectives.
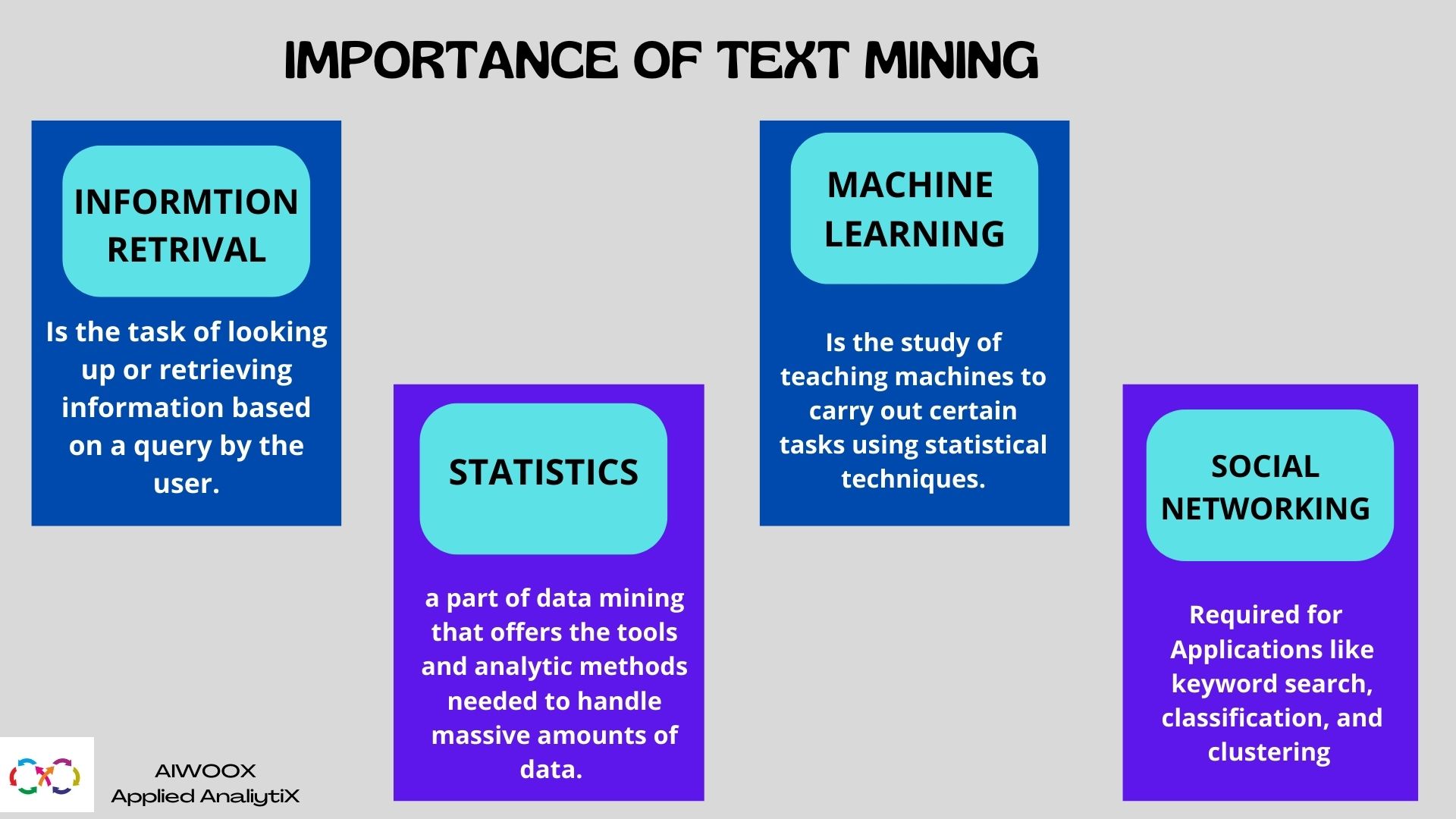
Text mining is a broad field that draws on a variety of methods and tools, including information extraction, data mining, deep learning , and programming languages. This multifaceted field includes data science, data mining, information retrieval, statistics, and mathematical languages. The summarizing, categorizing, and grouping of the discovered patterns, which can result in the required information extract, can be described as the foundation of text mining.
Text mining techniques have been widely used in web applications, classroom settings, and businesses. Usage is also included in a variety of sectors, including social media analytics, customer relationship management (CRM) systems, email filtration, analysis for product suggestions, and fraud detection. Utilize text analytics and mining to mine opinions, extract features, analyze sentiment, predict outcomes, and spot trends.
One of the most popular types of data in databases is text mining., depending on the database this data may be arranged as follows:
- Structured data: It is simpler to store and utilize this data for analysis and machine learning algorithms since it has been standardized into a tabular format with many rows and columns. Inputs such as names, addresses, and phone numbers can be found in structured data.
- Unstructured data: This data does not have a predefined data format. It can include text from sources, like social media or product reviews, or rich media formats like, video and audio files.
- Semi-structured data: As the name suggests, this data is a blend between structured and unstructured data formats. While it has some organization, it doesn’t have enough structure to meet the requirements of a relational database. Examples of semi-structured data include XML, JSON and HTML files.
EXAMPLES OF TEXT MINING:
- Cyber crime Prevention: The prevalence of communication tools and the Internet’s inherent privacy both raise the danger of crimes committed digitally. By providing additional context for the intelligence that is being supplied to business groups and law enforcement, text mining makes it easier for them to avoid cyber crime. They are able to identify actual threats and reduce the number of false positives brought on by out-of-context phrase usage.
- Streamlined Claims Investigation: In any field where the majority of data is gathered in text, text analytics is an incredibly powerful technique. For instance, there are various unusual text analysis use cases in the insurance industry. The most common use cases are risk engineering, claims automation, and policy review. Insurance companies can swiftly identify precise information with text mining that would take a person hours to do manually. It helps decrease risk exposure across portfolios and increases the efficiency of labor-intensive procedures.
- Filtering: Email is a reliable, quick, and relatively priced method of communication, but it has a downside: spam. Spam is a significant problem for internet service providers nowadays, driving up the cost of service administration and updating hardware and software.Spam serves as a malware entrance point for users and hinders productivity. By utilizing existing prior information, text mining techniques can be used to increase the efficiency of statistical filtering procedures. This not only results in more effective email handling, but it also significantly enhances user experience.
5 KEY STEPS OF TEXT MINING PROCESS:
- Data Cleaning: To ensure that all process data complies with the standard, teams must first clean it up. Time and money are lost due to poor insights and system failures brought on by faulty or insufficient data. Engineers will remove all filthy data from the organization’s data collection.
A number of data preparation and cleaning processes are used by the company, based on the tools those are accessible to them. For example, manually fill in any values that are missing or use the average of additional data to fill in a likely response. Teams will also use binning techniques eliminate erroneous data, identify outliers, and correct any inconsistencies. - Data Reduction for Data Quality: This routine procedure pulls pertinent data for data analysis and pattern analysis. During data reduction, engineers extract a tiny part of the data while maintaining its integrity. During this mining process, teams may use neural networks or other machine learning techniques.
Data compression, dimensional reduction, and numerical reduction are possible tactics. Engineers reduce the number of attributes in the analytics datasets through dimensional reduction. Teams replace the initial amount of data with a lower amount of data during numerical reduction. Engineers offer a compressed generalization of the gathered data when doing data compression. - Data Integration: At this stage, numerous specialists clean up more data in various databases. By doing this, inconsistencies in the data are further eliminated, and the quality of the data is ensured to satisfy business needs. To combine data, experts will employ data mining technologies like Microsoft SQL
- Data Transformation: Engineers modify data in this technique that is recognized in the industry to conform to mining objectives. To streamline data mining procedures and make it simpler to spot patterns in the final data set, they combine the preparatory data.
Data mapping and other data science approaches are included in data transformation. Smoothing, or removing noise from data, is one strategy. Aggregation, normalization, or discretionary are other well-liked methods. - Data Mining: In order to maximize knowledge discovery and uncover useful trends, businesses utilize data mining programmers to produce business intelligence. This is only feasible if a business fully utilizes big data and gathers the right kind of information. Before extracting the data, engineers apply intelligent patterns to the given data. They then use models to represent all the information. To assure accuracy, experts utilize clustering, classification, or other modeling techniques.
WHAT IS TEXT CLASSIFICATION?
Text classification is the process of assigning suitable categories from a preset list to natural language documents. The extraction of general tags from unstructured text is what it implies. These general tags are derived from a set of per-established categories. Text categorization is another name for text classification. Users can search and browse a website or application more quickly by categorizing products and content.
For instance, new articles can be sorted by subjects, help requests can be sorted by urgency, chat conversations can be sorted by language, brand mentions can be sorted by emotion, and so on. One of the core problems in natural language processing, text classification has a wide range of uses, including sentiment analysis, topic labeling, spam detection, and intent identification.
The primary writing styles in literature are represented by text types. Literary texts use imaginative language and imagery to entertain or otherwise interest the reader, as opposed to factual texts, which only aim to inform.
There are many aspects to literary writing, and many ways to analyze it, text classification includes four basic categories . They are:
- Narrative text type: The main goal of narrative is to entertain readers and keep them interested. Narrative text can be crafted to instruct or inform, to alter social perceptions or attitudes. Unlike chronicles, narratives situate people and characters in specific locations and times. However, unlike recounts, narratives also introduce one or more issues that must be handled at some point. “Story grammar” is the standard framework or fundamental design of narrative texts.
- Argumentative text type: A response to a problem based on evaluation and subsequent subjective judgment. It speaks of the arguments put up in favor of or against a situation. To persuade the reader to support one side, writers frequently engage in argumentation with opposing viewpoints. An effective method to frame an argument, particularly one that has been extensively written about, is to contrast the past and present.
- Literature: A literary text is a work of literature, like a book or a poem, that is intended to entertain or convey a story, like a fictional novel. Although poetry frequently has an aesthetic purpose as a text, it may also convey political statements or ideologies. Reading informational writings, which aim to inform rather than entertain, in contrast to literary literature.
- Expository text type: It aims to clarify or describe, i.e., to cognitively analyze and then synthesize complex data. An article on “Rhetoric: What is it and why do we study it?” might be an example.
If you did not select one of the truly good explanatory essay themes, there is a potential that your work may fall flat. Not all topics are intriguing or substantial enough to be fully explored in a paper. Make sure you put some thought into selecting a subject that will be covered in great detail and hold the readers’ attention.
TEXT CLASSIFICATION IN NATURAL LANGUAGE PROCESSING:
The practice of categorizing or grouping text data into categories is known as text classification. It plays this role as a key component of natural language processing. We are surrounded by text in the digital world we currently live in, whether it be on our social media accounts, in advertisements, on websites, in e-books, etc. Since most of this text data is unstructured, categorizing it can be quite helpful.
Here are some of the approaches based on Text Classification.
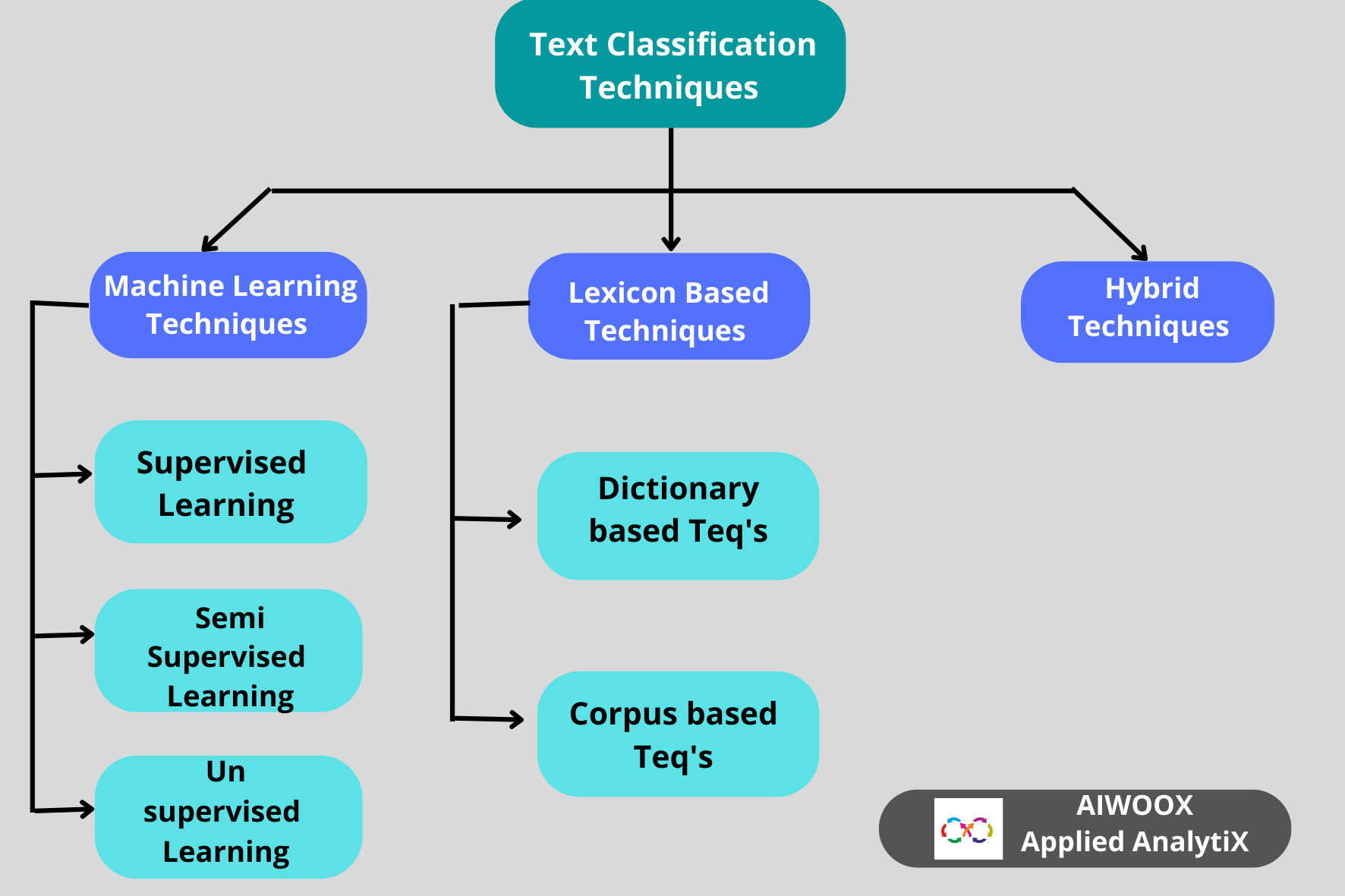
- Rule-based approaches: These methods use uniquely created language rules to categories content One method of grouping text is by making a list of words associated with a particular column and classifying the text according to how often these words appear. For instance, phrases like “fur,” “feathers,” “claws,” and “scales” could aid a zoologist in locating internet texts discussing animals. These methods take a long time to develop, require a lot of domain expertise, and are challenging to scale.
- Machine learning approaches: In order to forecast the categories of fresh text, machine learning can be used to train models on massive collections of text data. Feature extraction is the process of converting text data into numerical data so that models can be trained on it. There are several useful machine learning algorithms we can use for text classification. The most popular ones are:
1. Naive Bayes classifiers.
2.Support vector machines.
3.Deep learning algorithms.

TEXT CLASSIFICATION APPLICATIONS & USE CASES:
Text classification is used for a huge variety of jobs and has thousands of application cases. In some circumstances, data classification tools operate in the background to improve daily-used app features (like email spam filtering). Other times, marketers, product managers, engineers, and salespeople utilize classifiers to automate business procedures and avoid spending countless hours manually analyzing data.
The foregoing are some of the most popular uses and applications for text classification:
- Detecting urgent issues: Businesses can make sense of massive amounts of data with the aid of text categorization by employing methods like aspect-based sentiment analysis to determine what people are discussing and how they are discussing each topic. For instance, a potential PR problem, a client who is about to leave, complaints about a bug, or downtime that affects a sizable number of clients.
- Automating Customer Support Processes: A sustainable and expanding business is built on the foundation of creating a positive client experience. People are 93% more likely to become repeat customers at businesses with exceptional customer service, according to Hub spot.
According to the study’s findings, 80% of respondents to the poll indicated they had ceased doing business with a company as a result of a bad customer experience.By automating tasks that are better left to computers, text classification can assist support teams in delivering an excellent experience while freeing up valuable time that can be spent on more important work. - Listening to Voice of Customer (VoC): Both qualitative and quantitative data were collected, and while NPS scores are simple to assess, open-ended responses call for a more in-depth analysis employing text classification techniques. Machine learning can handle open-ended consumer input quickly in place of depending on humans to assess the voice of customer data.
CONCLUSION
Text mining:
Text mining algorithms will provide useful and structured data, which can reduce time and cost. Hidden information in social networking sites, bioinformatics, internet security, etc., is identified using text mining, which is a major challenge in these fields.
Text Classification:
A fundamental machine learning problem with several applications is text classification. We have divided the workflow for text classification into a series of steps in this guide. We have provided a tailored method for each stage based on the features of your particular datasets.